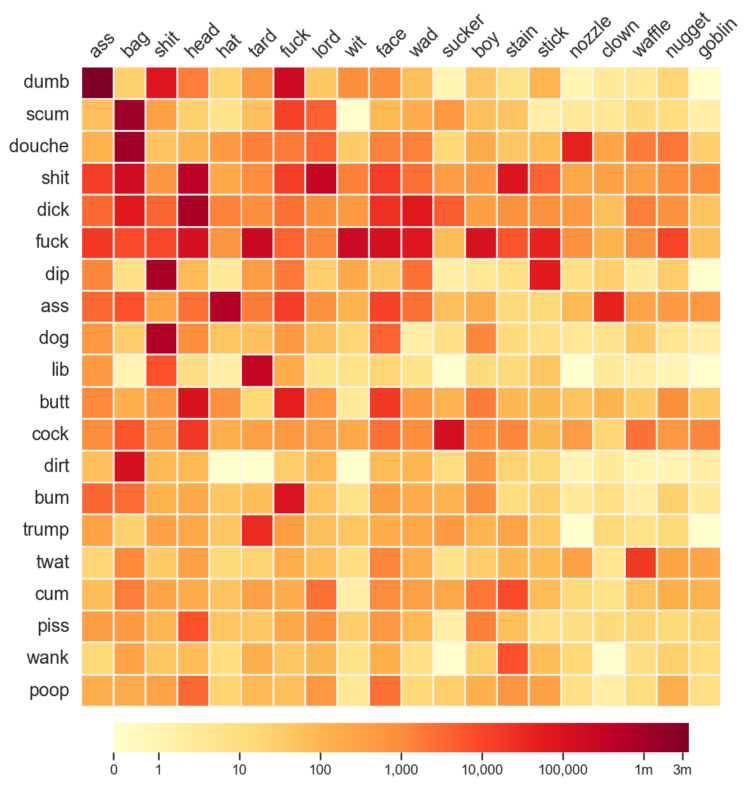
As you know, Reddit is typically a sophisticated place of kind and pleasant conversation. So Colin Morris analyzed the usage of compound pejoratives in Reddit comments:
The full “matrix” of combinations is surprisingly dense. Of the ~4,800 possible compounds, more than half occurred in at least one comment. The most frequent compound, dumbass, appears in 3.6 million comments, but there’s also a long tail of many rare terms, including 444 hapax legomena (terms which appear only once in the dataset), such as pukebird, fartrag, sleazenozzle, and bastardbucket.
Stay classy.
Tags: Colin Morris, humor, language, Reddit


 On April Fool’s Day, Reddit launched a blank canvas that users could add a colored pixel every few minutes. It ran for 72 hours, and the
On April Fool’s Day, Reddit launched a blank canvas that users could add a colored pixel every few minutes. It ran for 72 hours, and the 

21Jul / 2015
Download data for 1.7 billion Reddit comments
There's been all sorts of weird stuff going on at Reddit lately, but who's got time for that when you can download 1.6 billion comments left on Reddit, since 2007 through May 2015?
Timestamp, comment ids, controversiality score, and of course the comment text. It's 5 gigabytes compressed and available over torrent.
Git er done.
Tags: comments, Reddit
Posted by Nathan Yau in comments, Data Sources, Reddit
Tags: comments, Reddit
Permalink