“Translating the genetic code is the nexus connecting pre-biotic chemistry to biology.” — Dr. Charles Carter
Last week we discussed the general question of how the genetic code evolved, and noted that the idea of the code as merely a frozen accident — an almost completely arbitrary key/value pairing of codons and amino acids — is not consistent with the evidence that has been amassed over the past three decades. Instead, there are deeper patterns in the code that go beyond the obvious redundancy of synonymous codons. These patterns give us important clues about the evolutionary steps that led to the genetic code that was present in the last universal common ancestor of all present-day life.
Charles Carter and his colleague Richard Wolfenden at the University of North Carolina Chapel Hill recently authored two papers that suggest the genetic code evolved in two key stages, and that those two stages are reflected in two codes present in the acceptor stem and anti-codon of tRNAs.
In the first part of my interview with Dr. Carter, he reviewed some of previous work in this field. In the present installment, he comments on the important results that came out of his two recent studies with Dr. Wolfenden. But before we continue with the interview, let’s review the main findings of the papers.
The key result is that there is a strong relationship between the nucleotide sequence of tRNAs, specifically in the acceptor stem and the anti-codon, and the physical properties of the amino acids with which those tRNAs are charged. In other words, tRNAs do more than merely code for the identity of amino acids. There is also a relationship between tRNA sequence and the physical role performed by the associated amino acids in folded protein structures. This suggests that, as Dr. Carter summarized it, “Our work shows that the close linkage between the physical properties of amino acids, the genetic code, and protein folding was likely essential from the beginning, long before large, sophisticated molecules arrived on the scene.” Perhaps it also suggests – this is my possibly unfounded speculation – that today’s genetic code was preceded by a more coarse-grained code that specified sets of amino acids according to their physical functions, rather than their specific identity.
How do the papers show this? To oversimplify a bit, the logic of the two studies proceeds in two steps. The first step is to determine the relevant amino acid properties. The second is to ask whether those properties correlate with tRNA sequence.
The first paper examined amino acid hydrophobicities and their temperature dependence. The rationale for choosing hydrophobicity as a relevant physical property is that it is closely related to the role different amino acid structures play in 3D protein structures – more hydrophobic residues are buried in globular cores, and so on. But in order to understand if hyrdophobicity played a similar role in protein structure during the early evolution of the genetic code — in relatively warm conditions of the RNA (or RNA plus peptide) World — Wolfenden and his team determined amino acid hydrophobicities at high temperatures. They concluded that the temperature dependence of hydrophobicities “are such that they would have tended to minimize the otherwise disruptive effects of a changing thermal environment on the evolution of protein structure.”
In the second paper, Carter and Wolfenden used this data to build a regression model of the relationship between the physical properties of amino acids (as defined by two key free energies) and the tRNA sequences. The regression analysis shows that there are two independent tRNA codes:
“The anticodon encodes the hydrophobicity of each amino acid side-chain as represented by its water-to-cyclohexane distribution coefficient, and this relationship holds true over the entire temperature range of liquid water. The acceptor stem codes preferentially for the surface area or size of each side-chain, as represented by its vapor-to-cyclohexane distribution coefficient.”
So what does this tell us about the evolution of the genetic code? In comments to the University of North Carolina, Dr. Carter explained it nicely:
Dr. Wolfenden established physical properties of the twenty amino acids, and we have found a link between those properties and the genetic code. That link suggests to us that there was a second, earlier code that made possible the peptide-RNA interactions necessary to launch a selection process that we can envision creating the first life on Earth.
For more detail, you can go read the papers or check out the good non-technical summary by the UNC news office. The news piece includes additional comments by Drs. Wolfenden and Carter, some of which I’ve quoted above.
And now on to part two of my interview with Dr. Carter:
MW: You describe two codes in tRNA sequences that specify amino acid properties, one in the acceptor stem and one in the anti-codon. How do these two codes work?
CC: This is a wonderful question, one of many to which we do not claim to have an answer. We are pretty confident that the relationships we describe are real and that they therefore signal a multi-stage evolution from stereochemical coding first to indirect coding via an adaptor RNA related to tRNA, and finally to the ability to read a blueprint in mRNA by recognizing the appropriate triplet of bases (which is the first stage that can be described as “genetic”). Here are several thoughts:
a. What we report are actually strong correlations; they are novel, but by themselves they lack explanatory power.
b. “How they work…” has several different connotations. At one level, they work simply by the strong correlations, but that is not what you intended for me to answer. At the level of the modern code, the answer is also pretty clear, as the 3D structures have been determined for many key intermediates in the translation of messages.
c. An important component of the modern translation system that we more or less assume in our treatment is the ribosome, which is essentially an RNA enzyme for making peptide bonds combined with a complex information processor that reads mRNA. Although we do not comment extensively on this aspect of the generation of the code, the evolution of the ribosome itself must have played an important role. There are two schools of thought on the evolution of the ribosome. One holds that the peptide bond-making machine (the 50S subunit) came first (Petrov, A. S., et al., 2014, and Petrov, A. S. & Williams, L. D., 2015). The other holds that the decoding 30S subunit preceded the appearance of the large ribosomal subunit (Harish, A. & Caetano-Anollés, G., 2012).
d. The key mystery in my mind is whether, and if so, how molecules smaller than tRNA that contained only the acceptor stem might have been used to align amino acids in somewhat the same way that the acceptor stems are aligned within the 50S ribosomal subunit, but using various aspects of the pairing of acceptor stems, rather than downloading this task to the anticodon within the 30S subunit. It is quite difficult for me to imagine how such alignments might have obeyed sequences in an RNA blueprint. Yarus has, however, described one possible model for the evolution of templating by messenger RNA in the reference cited above in 2b.
MW: You and Dr. Wolfenden decided to measure an important amino acid property, hydrophobicity, at a much higher temperature than is typical – 100˚ C. Why did you and Dr. Wolfenden do these measurements at this higher temperature, and what did you discover about hydrophobicity?
CC: This is a wonderful question for my co-author, and I’ll give you my interpretation. Dr. Wolfenden is somewhat more convinced than I am that life began almost as soon as the earth cooled to allow liquid water. There is much magnificent (and controversial!) thermodynamics associated with what happens to hydrophobicities at 100 C, especially because dyed-in-the-wool physical chemists claim that the hydrophobic effect, per se, goes away at 100 C. One thing that seems certain is that the range of hydrophobicities for different amino acids narrows substantially at higher temperatures. However, they narrow in ways that do not disrupt the correlations we established with the coding properties of the anticodon.
MW: What do your results tell us about how the genetic code evolved? If we discovered DNA-based life elsewhere, say, on Mars, how similar would the Martian genetic code be to the one on earth — assuming life originated independently in both places?
CC: I myself am something of a “terrestrial chauvinist” by which I mean that the long arm of coincidence means something. I believe that much of what we have learned about life on earth is so closely aligned with (perhaps unknown) physical laws that we would recognize life elsewhere in the universe as being very much like life here. In particular, I am pretty confident that it would be carbon based, and the chemical free energy would be exchanged via phosphate esters, as it is on earth. It would be based on polypeptides and polynucleotides, because the former have an incredible manifold of functional variation in the space of folded proteins for controlling differential binding and catalysis, whereas nucleic acids have rock solid information storage capacity. The likelihood that their respective thermodynamically stable helical structures are structurally complementary leads me to believe that these two polymers are uniquely suited for life. Further, the properties of the four nucleic acid bases appear to be unique enough that life elsewhere in the universe would be made from the same four bases.
Ironically, and despite my terrestrial chauvinism, I really don’t think we know enough yet to make educated guesses on the question you pose here. Although our work and the previous work by Delarue do thaw the frozen accident somewhat, I think we know too little to say with any confidence that the code that evolved on earth has such advantages that it would always win the competition elsewhere. Many studies on the code have shown that although it is extremely robust to mutation (Freeland, S. J. & Hurst, L. D., 1998), it cannot be unique, as the combinatorial space of codes is so vast.
Filed under: Curiosities of Nature Tagged: evolution, genetic code







 The genetic code is one of biology’s few universals*, but rather than being the result of some deep underlying logic, it’s often said to be a “frozen accident” — the outcome of evolutionary chance, something that easily could have turned out another way. This idea, though it’s often repeated, has been challenged for decades. The accumulated evidence shows that the genetic code isn’t as arbitrary as we might naively think. And more importantly, this evidence also offers some tantalizing clues to how the genetic code came to be.
The genetic code is one of biology’s few universals*, but rather than being the result of some deep underlying logic, it’s often said to be a “frozen accident” — the outcome of evolutionary chance, something that easily could have turned out another way. This idea, though it’s often repeated, has been challenged for decades. The accumulated evidence shows that the genetic code isn’t as arbitrary as we might naively think. And more importantly, this evidence also offers some tantalizing clues to how the genetic code came to be.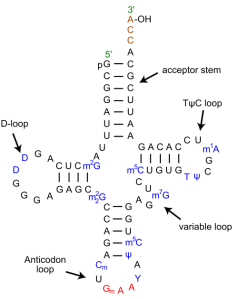














{kind=link}