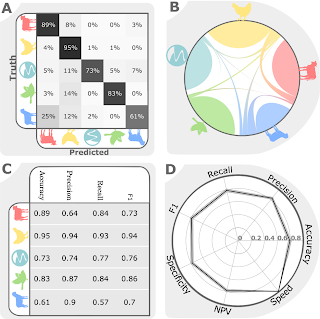
For Knowing Machines, an ongoing research project that examines the innards of machine learning systems, Christo Buschek and Jer Thorp turn attention to LAION-5B. The large image dataset is used to train various systems, so it’s worth figuring out where the dataset comes from and what it represents.
As artists, academics, practitioners, or as journalists, dataset investigation is one of the few tools we have available to gain insight and understanding into the most complex systems ever conceived by humans.
This is why advocating for dataset transparency is so important if AI systems are ever going to be accountable for their impacts in the world.
If articles covering similar themes have confused you or were too handwavy, this one might clear that up. It describes the system and steps more concretely, so you finish with a better idea of how systems can end up with weird output.
Tags: bias, Knowing Machines, LAION-5B, machine learning
 In an automated job climate that analyzes resumes and inspects social profiles, it can be a challenge to find the job that’s right for you. Luckily, Jess Peter for The Pudding put together a
In an automated job climate that analyzes resumes and inspects social profiles, it can be a challenge to find the job that’s right for you. Luckily, Jess Peter for The Pudding put together a