This is a joint post by Justin Power, Guido Grimm, and Johann-Mattis List.
Like in biology, we have two basic possibilities for studying how languages evolve:
While most studies would probably aim to employ a set of universal comparanda, the practice often requires a compromise solution in which some non-universal characteristics are added. This holds, for example, for the idea of a core genome in biology, which ends up being so small in overlap across all living species that it makes little sense to compute phylogenies based on it, except for for closely related species (Dagan and Martin 2006). Another example is the all-inclusive matrices that are used to establish evolutionary relationships of extinct animals characterized by high levels of missing data (eg. Tschopp et al. 2015; Hartman et al. 2019). The same holds for historical linguistics, with the idea of a basic lexicon or basic vocabulary, represented by a list of basic concepts that are supposed to be expressed by simple words in every human language (Swadesh 1955), given that the number of concepts represented by simple words shared across all human languages is extremely small (Hoijer 1956).
Apart from the problem that basic vocabulary concepts occurring in all languages may be extremely limited, test items need to fulfill additional characteristics that may not be easy to find,in order to be useful for phylogenetic studies. They should, for example, be rather resistant to processes of lateral transfer or borrowing in linguistics. They should preferably be subject to neutral evolution, since selective pressure may lead to parallel but phylogenetically independent processes (in biology known as convergent evolution) that are difficult to distinguish and can increase the amount of noise in the data (homoplasy).
Selective pressure, as we might find, for example, in a specific association between certain concepts and certain sounds across a large phygenetically independent sample of human languages, is rarely considered to be a big problem in historical linguistics studies dealing with the evolution of spoken languages (see Blasi et al. 2016 for an exception). In sign language evolution, however, the problem may be more acute because of a similar iconic motivation of many lexical signs in phylogenetically independent sign languages (Guerra Currie et al. 2002), as well as the representation of concepts such as body parts and pronouns using indexical signs with similar forms. This latter characteristic of all known sign languages has led to the design of a basic vocabulary list that differs from those traditionally used in the historical linguistics of spoken languages (Woodward 1993); and we know of only one proposal attempting to address the problem of iconicity in sign languages for phylogenetic research (Parkhurst and Parkhurst 2003).
Like in biology, we have two basic possibilities for studying how languages evolve:
- We set up a list of universal comparanda. These should occur in all languages and show a high enough degree of variation that we can use them as indicators of how languages have evolved;
- We create individual lists of comparanda. These are specific for certain language groups that we want to study.
While most studies would probably aim to employ a set of universal comparanda, the practice often requires a compromise solution in which some non-universal characteristics are added. This holds, for example, for the idea of a core genome in biology, which ends up being so small in overlap across all living species that it makes little sense to compute phylogenies based on it, except for for closely related species (Dagan and Martin 2006). Another example is the all-inclusive matrices that are used to establish evolutionary relationships of extinct animals characterized by high levels of missing data (eg. Tschopp et al. 2015; Hartman et al. 2019). The same holds for historical linguistics, with the idea of a basic lexicon or basic vocabulary, represented by a list of basic concepts that are supposed to be expressed by simple words in every human language (Swadesh 1955), given that the number of concepts represented by simple words shared across all human languages is extremely small (Hoijer 1956).
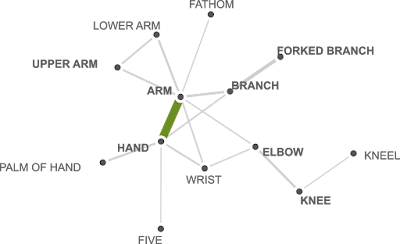 |
| Figure 1: All humans have hands and arms but some words for ‘hands’ and ‘arms’ address different things (see our previous post "How languages loose body parts"). |
Apart from the problem that basic vocabulary concepts occurring in all languages may be extremely limited, test items need to fulfill additional characteristics that may not be easy to find,in order to be useful for phylogenetic studies. They should, for example, be rather resistant to processes of lateral transfer or borrowing in linguistics. They should preferably be subject to neutral evolution, since selective pressure may lead to parallel but phylogenetically independent processes (in biology known as convergent evolution) that are difficult to distinguish and can increase the amount of noise in the data (homoplasy).
Selective pressure, as we might find, for example, in a specific association between certain concepts and certain sounds across a large phygenetically independent sample of human languages, is rarely considered to be a big problem in historical linguistics studies dealing with the evolution of spoken languages (see Blasi et al. 2016 for an exception). In sign language evolution, however, the problem may be more acute because of a similar iconic motivation of many lexical signs in phylogenetically independent sign languages (Guerra Currie et al. 2002), as well as the representation of concepts such as body parts and pronouns using indexical signs with similar forms. This latter characteristic of all known sign languages has led to the design of a basic vocabulary list that differs from those traditionally used in the historical linguistics of spoken languages (Woodward 1993); and we know of only one proposal attempting to address the problem of iconicity in sign languages for phylogenetic research (Parkhurst and Parkhurst 2003).
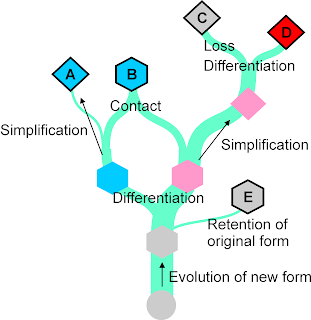 |
| Figure 2: Basic processes in the evolution of languages, spoken or signed (see our previous post How languages loose body parts). |
All in all, it seems that there may be no complete solution for a list of lexical comparanda for all human languages, including sign languages, given the complexities of lexical semantics, the high variability in expression among the languages of the world (see Hymes 1960 for a detailed discussion on this problem), and the problems related to selective pressures highlighted above. Scholars have proposed alternative features for comparing languages, such as grammatical properties (Longobardi et al. 2015) or other "structural" features (Szeto et al. 2018), but these are either even more problematic for historical language comparison—given that it is never clear if these alternative features have evolved independently or due to common inheritance—or they are again based on a targeted selection for a certain group of languages in a certain region.
Targeted comparanda
If there is no universal list of features that can be used to study how languages have evolved, we have to resort to the second possibility mentioned above, by creating targeted lists of comparanda for the specific language groups whose evolution we want to study. When doing so, it is best to aim at a high degree of universality in the list of comparanda, even if one knows that complete universality cannot be achieved. This practice helps to compare a given study with alternative studies; it may also help colleagues to recycle the data, at least in part, or to merge datasets for combined analyses, if similar comparanda have been published for other languages.
But there are cases where this is not possible, especially when conducting studies where no previous data have been published, and rigorous methods for historical language comparison have yet to be established. Sign languages can, again, be seen as a good example for this case. So far, few phylogenetic studies have addressed sign language evolution, and none have supplied the data used in putting forward an evolutionary hypothesis. Furthermore, because the field lacks unified techniques for the transcription of signs, it is extremely difficult to collect lexical data for a large number of sign languages from comparable glossaries, wordlists, and dictionaries, the three primary sources, apart from fieldwork, that spoken language linguists would use in order to start a new data collection. We are aware of one comparative database with basic vocabulary for sign languages that is currently being built (Yu et al. 2018), and that may represent lexical items in a way that can be compared efficiently, but these data have not yet been made available to other researchers.
Sign languages
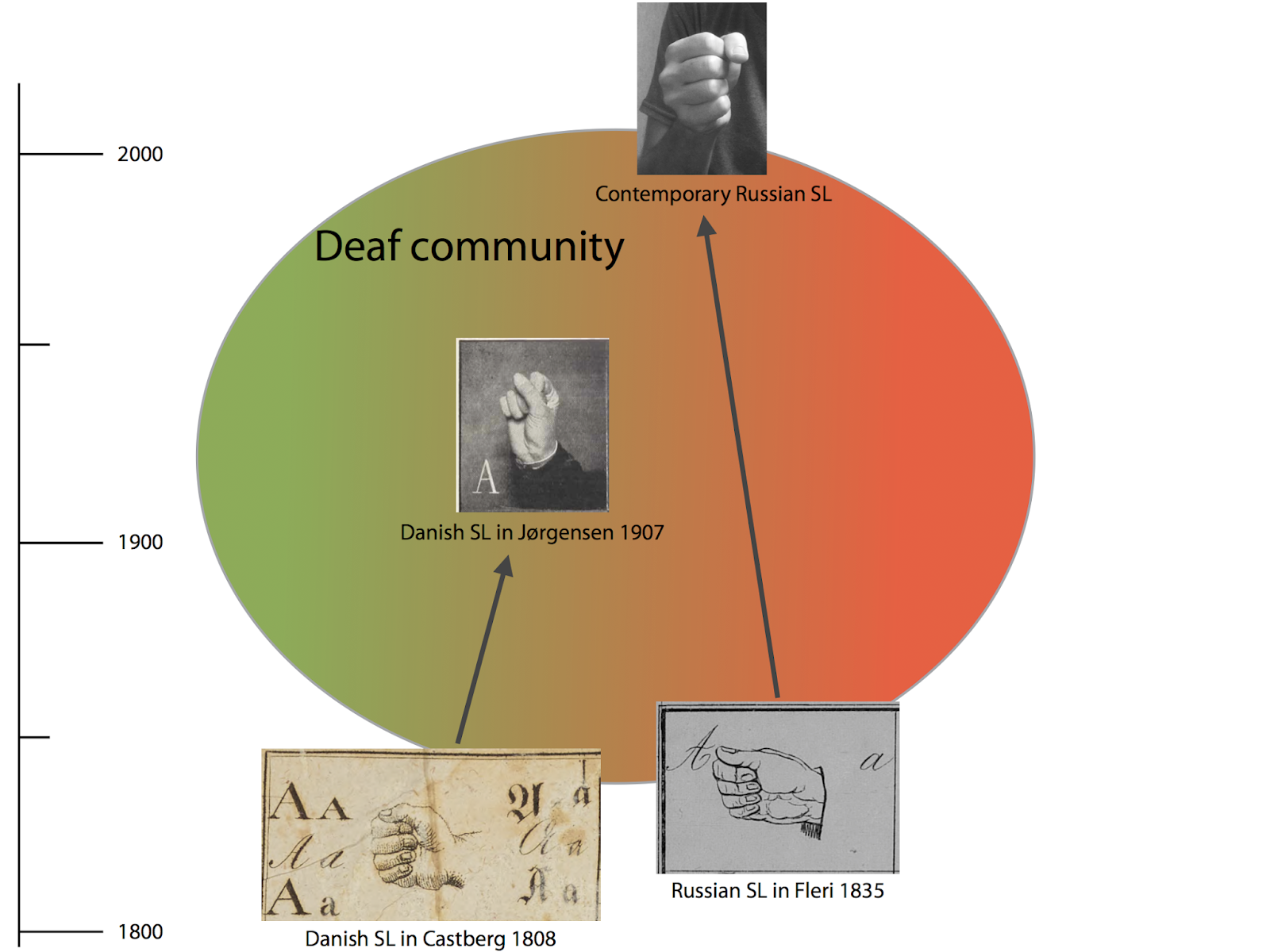
When Justin Power approached Mattis about three years ago, asking if he wanted to collaborate on a study relating to sign language evolution, we quickly realized that it would be infeasible to gather enough lexical data for a first study. Tiago Tresoldi, a post-doc in our group, suggested the idea of starting with sign language manual alphabets instead. From the start, it was clear that these manual alphabets might have certain disadvantages — because they are used to represent written letters of a different language, they may constitute a set of features evolving independently from the sign language itself.
 |
| Figure 3: Processes shaping manual alphabets. The evolution of signed concepts may be affected by the same, leading to congruent patterns, or different processes, leading to incongruent differentiation patterns (see our previous post: Stacking networks based on sign language manual alphabets). |
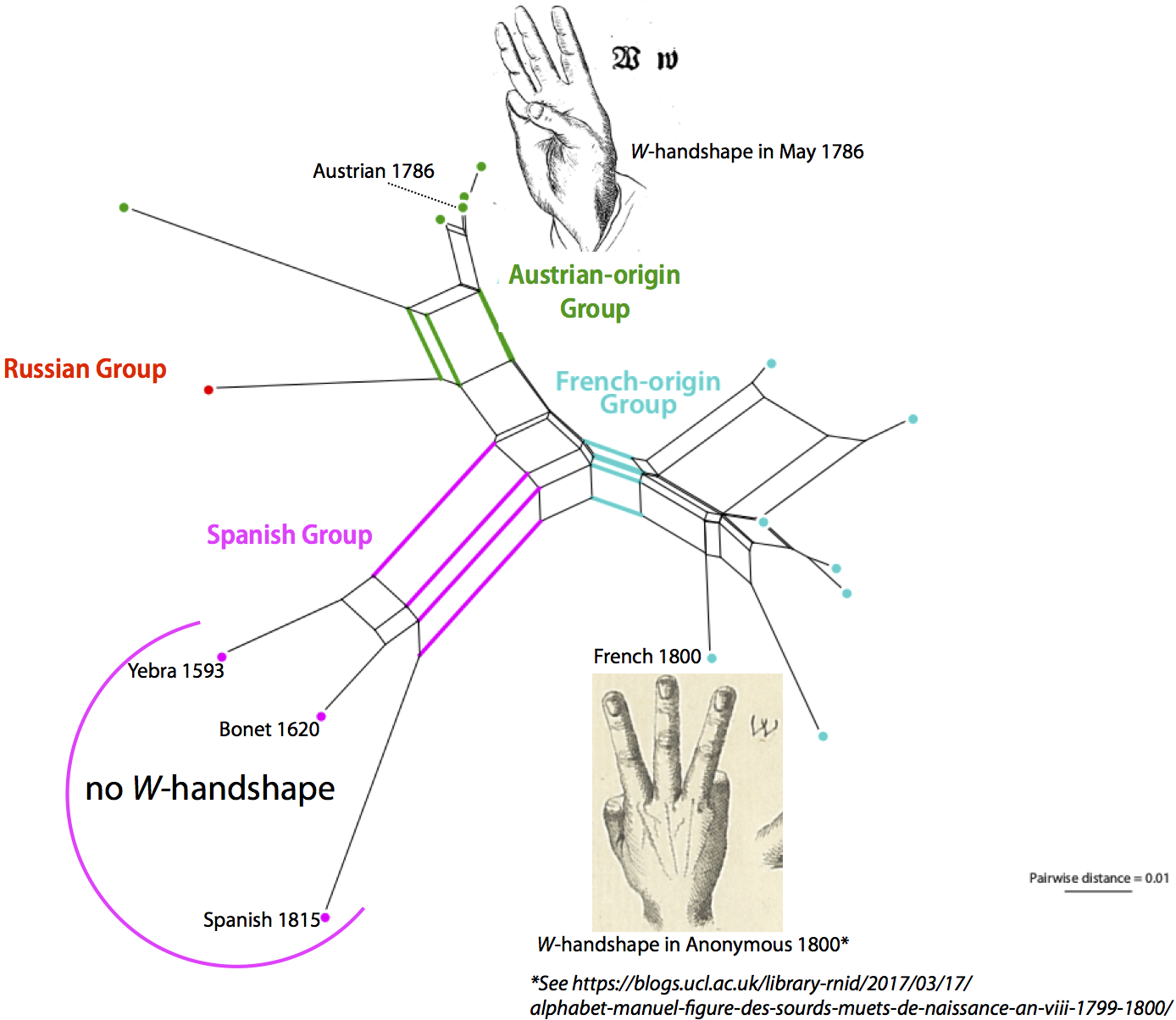
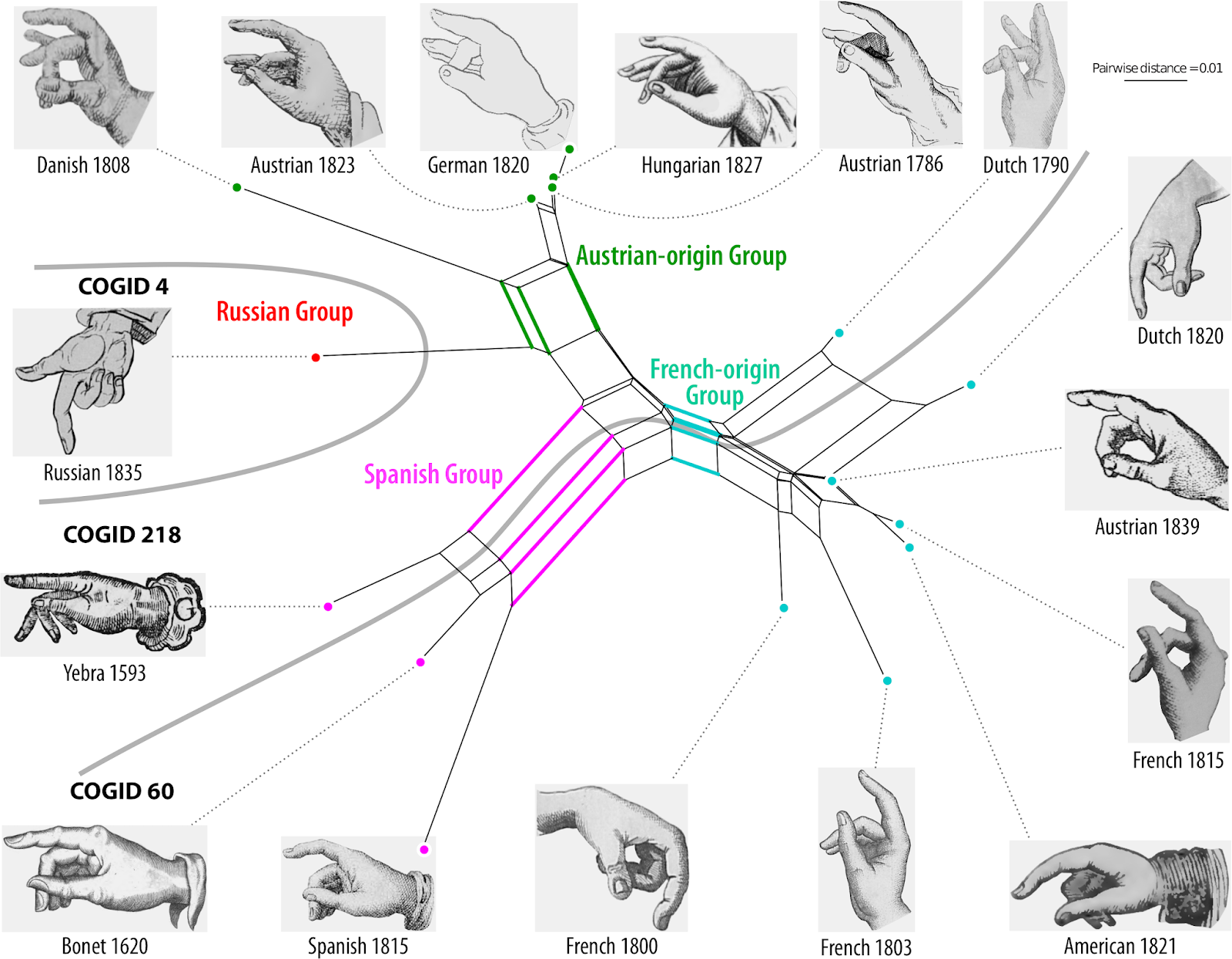
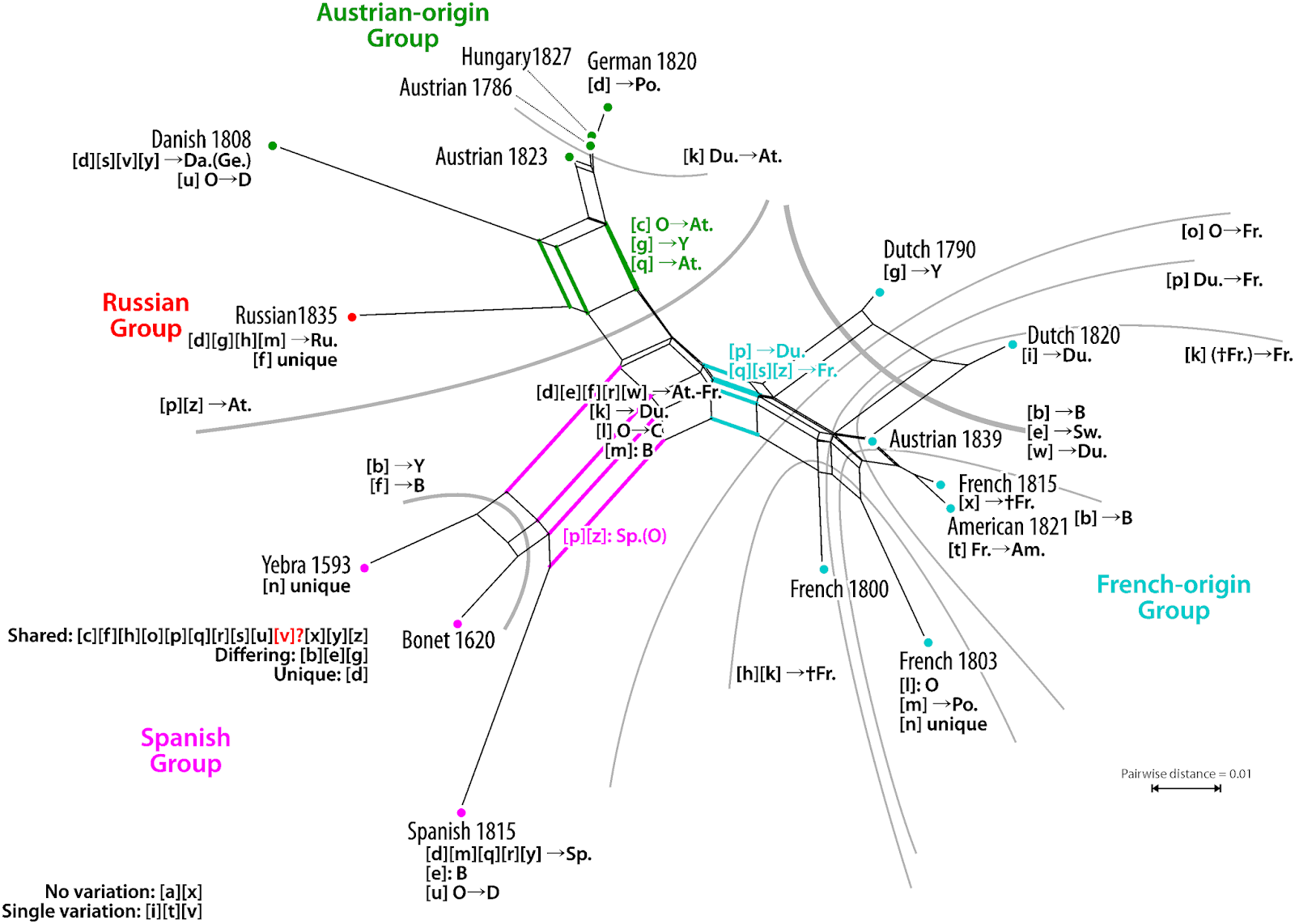
But on the other hand, the data had many advantages. First, a sufficient number of examples for various European sign languages were available in online databases that could be transcribed in a uniform way. Second, the comparison itself was facilitated, since in most cases there was no ambiguity about which “concepts” to compare, in contrast to what one would encounter in a comparison of lexical entries. For example, an “a” is an “a” in all languages. Third, it turned out that for quite a few languages, historical manual alphabets could be added to the sample. This point was very important for our study. Given that scholars still have limited knowledge regarding the details of sign change in sign language evolution, it is of great importance to compare sources of the same variety, or those assumed to be the same, across time—just as spoken language linguists compared Latin with Spanish and Italian in order to study how sounds change over time. And finally, manual alphabets in fact constitute an integrated part of many sign languages that may, for example, contribute to the forms of lexical signs, making the idea more plausible that an understanding of the evolution of manual alphabets could be informative about the evolution of sign languages as a whole.
 |
| Figure 4: Early evolution of handshapes used to sign ‘g’ (see our previous post: Character cliques and networks – mapping haplotypes of manual alphabets). |
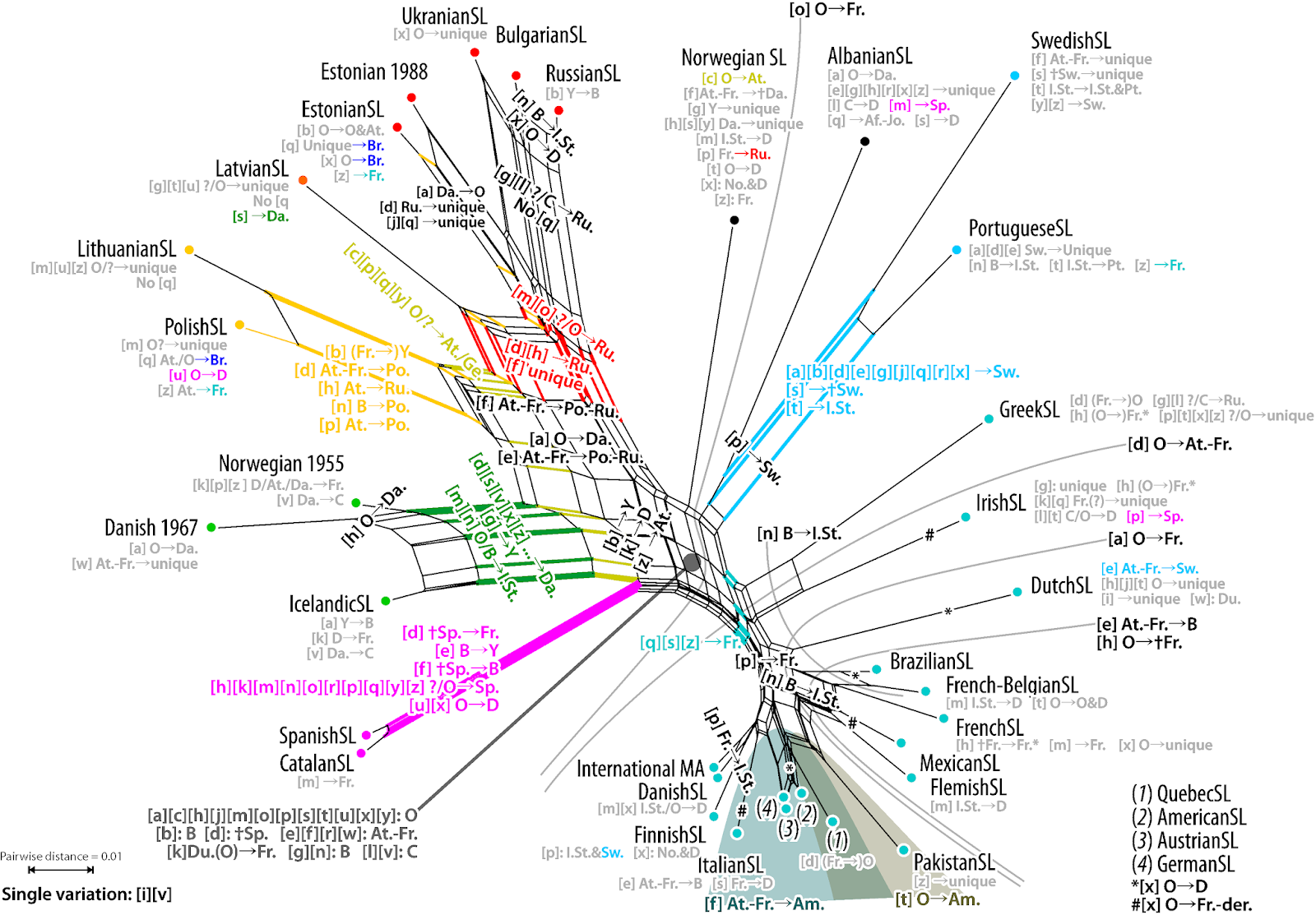
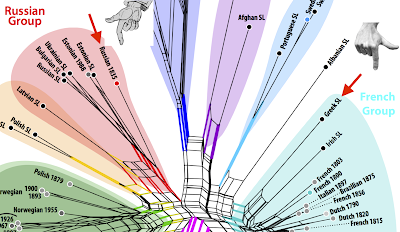
Guido later joined our team, providing the expertise to analyze the data with network methods that do not assume tree-like evolution a priori. We therefore thought that we had done a rather good job when our pilot study on the evolution of sign language manual alphabets, titled Evolutionary Dynamics in the Dispersal of Sign Languages, finally appeared last month (Power et al. 2020). We identified six basic lineages from which the manual alphabets of the 40 contemporary sign languages developed. The term "lineage" was deliberately chosen in this context, since it was unclear whether the evolution of the manual alphabets should be seen as representative of the evolution of the sign languages as a whole. We also avoided the term "family", because we were wary of making potentially unwarranted assumptions about sign language evolution based on theories in historical linguistics.
 |
| Figure 5: The all-inclusive Neighbor-net (taken from Power et al. 2020). |
While the study was positively received by the popular media, and even made it onto the title page of the Süddeutsche Zeitung (one of the largest daily newspapers in Germany), there were also misrepresentations of our results in some media channels. The Daily Mail (in the UK), in particular, invented the claim that all human sign languages have evolved from five European lineages. Of course, our study never said this, nor could it have, since only European sign languages were included in our sample. (We included three manual alphabets representing Arabic-based scripts from Afghan, Jordanian, and Pakistan Sign Languages, where there was some indication that these may have been informed by European sources.)
Study of phylogenetics
While we share our colleagues’ distaste for the Daily Mail’s likely purposeful misrepresentation (in the end, unfortunately, it may have achieved its purpose as click bait), some colleagues went a bit further. One critique that came up in reaction to the Daily Mail piece was that our title opens the door to misinterpretation, because we had only investigated manual alphabets and, hence, cannot say anything about the "evolutionary dynamics of sign languages".
While the title does not mention manual alphabets, it should be clear that any study on evolution is based on a certain amount of reduction. Where and how this reduction takes place is usually explained in the studies. Many debates in historical linguistics of spoken languages have centered around the question of what data are representative enough to study what scholars perceive as the "overall evolution" of languages; and scholars are far from having reached a communis opinio in this regard. At this point, we simply cannot answer the question of whether manual alphabets provide clues about sign language evolution that contrast with the languages’ "general" evolution, as expressed, for example, in selecting and comparing 100 or 200 words of basic vocabulary. We suspect that this may, indeed, be the case for some sign languages, but we simply lack the comparative data to make any claims in this respect.
 |
| Figure 6: Evolution doesn’t mean every feature has to follow the same path: a synopsis of molecular phylogenies inferred for oaks, Quercus, and their relatives, Fagaceae (upcoming post on Res.I.P.) While nuclear differentiation matches phenotypic evolution and the fossil record (likely monophyla in bold font), the evolution of the plastome is partly decoupled (gray shaded: paraphyletic clades). Likewise, we can expect that different parts of languages, such as manual alphabets vs. core “lingome” of sign languages, may indicate different relationships. |
The philosophical question, however, goes much deeper, to the "nature" of language: What constitutes a language? What do all languages have in common? How do languages change? What are the best ways to study how languages evolve?
One approach to answering these questions is to compare collectible features of languages ("traits" in biology), and to study how they evolve. As the field develops, we may find that the evolution of a manual alphabet does not completely coincide with the evolution of the lexicon or grammar of a sign language. But would it follow from such a result that we have learned nothing about the evolution of sign languages?
There is a helpful analogy in biology: we know that different parts of the genetic code can follow different evolutionary trajectories; we also know that phenotype-based phylogenetic trees sometimes conflict with those based on genotypes. But this understanding does not stop biologists from putting forward evolutionary hypotheses for extinct organisms, where only one set of data is available (phenotypes; Tree of Life). Furthermore, such conflicting results may lead to a more comprehensive understanding of how a species has evolved.
 |
| Figure 7: A likely case of convergence: the sign for “г” in Russian and Greek Sign Language, visually depicting the letter (see our previous post Untangling vertical and horizontal processes in the evolution of handshapes). Complementing studies of signed concepts may reveal less obvious cases of convergence (or borrowing). |
Because we felt the need to further clarify the intentions of our study, and to answer some of the criticism raised about the study on Twitter, we decided to prepare a short series of blog posts devoted to the general question of "How should one study language evolution" (or more generally: "How should one study evolution?"). We hope to take some of the heat out of the discussion that evolved on Twitter, by inviting those who raised critiques about our study to answer our posts in the form of comments here, or in their own blog posts.
The current blog post can thus be understood as an opening for more thoughts and, hopefully, more fruitful discussions around the question of how language evolution should be studied.
In that context, feel free to post any questions and critiques you may have about our study below, and we will aim to pick those up in future posts.
References
Damián E. Blasi and Wichmann, Søren and Hammarström, Harald and Stadler, Peter and Christiansen, Morten H. (2016) Sound–meaning association biases evidenced across thousands of languages. Proceedings of the National Academy of Science of the United States of America 113.39: 10818-10823.
Dagan, Tal and Martin, William (2006) The tree of one percent. Genome Biology 7.118: 1-7.
Guerra Currie, Anne-Marie P. and Meier, Richard P. and Walters, Keith (2002) A cross-linguistic examination of the lexicons of four signed languages. In R. P. Meier, K. Cormier, & D. Quinto-Pozos (Eds.), Modality and Structure in Signed and Spoken Languages (pp.224-236). Cambridge University Press.
Hoijer, Harry (1956) Lexicostatistics: a critique. Language 32.1: 49-60.
Hymes, D. H. (1960) Lexicostatistics so far. Current Anthropology 1.1: 3-44.
Longobardi, Giuseppe and Ghirotto, Silva and Guardiano, Cristina and Tassi, Francesca and Benazzo, Andrea and Ceolin, Andrea and Barbujan, Guido (2015) Across language families: Genome diversity mirrors linguistic variation within Europe. American Journal of Physical Anthropology 157.4: 630-640.
Parkhurst, Stephen and Parkhurst, Dianne (2003) Lexical comparisons of signed languages and the effects of iconicity. Working Papers of the Summer Institute of Linguistics, University of North Dakota Session, vol. 47.
Power, Justin M. and Grimm, Guido and List, Johann-Mattis (2020) Evolutionary dynamics in the dispersal of sign languages. Royal Society Open Science 7.1: 1-30. DOI: 10.1098/rsos.191100
Swadesh, Morris (1955) Towards greater accuracy in lexicostatistic dating. International Journal of American Linguistics 21.2: 121-137.
Szeto, Pui Yiu and Ansaldo, Umberto and Matthews, Steven (2018) Typological variation across Mandarin dialects: An areal perspective with a quantitative approach. Linguistic Typology 22.2: 233-275.
Woodward, James (1993) Lexical evidence for the existence of South Asian and East Asian sign language families. Journal of Asian Pacific Communication 4.2: 91-107.